Building a front-end sandbox for OpenAI's Codex
Automatic code generation with the press of a button

GitHub Copilot and Replit Ghostwriter have been changing the face of programming by leveraging the power of OpenAI's Codex model. They can explain code using natural language, fix bugs in a matter of seconds, and generate entire functions or files from a single prompt. The only problem with these services is the high cost -- Copilot and Ghostwriter both cost $100+ yearly to use.
Over the past week, I've scraped enough time together to make a quick sandbox webpage that lets me play around with Codex's API. The requests are all done in the front-end and it takes almost no setup at all - just fetch() and you have the code.

If you write a function definition and the description, Codex does surprisingly well:

It can even write about and explain code, and can handle languages other than Python:
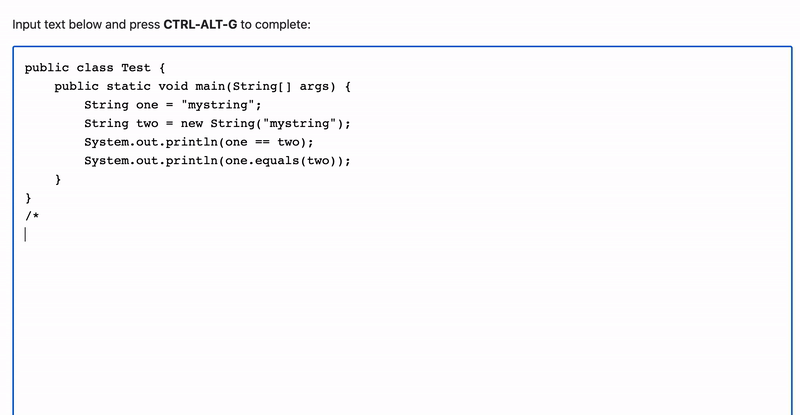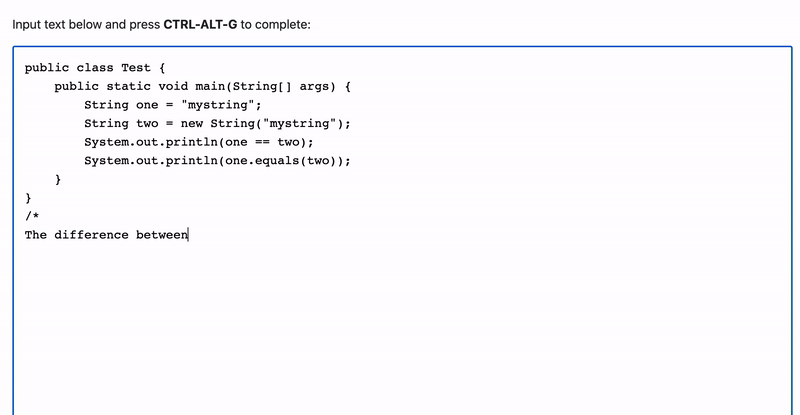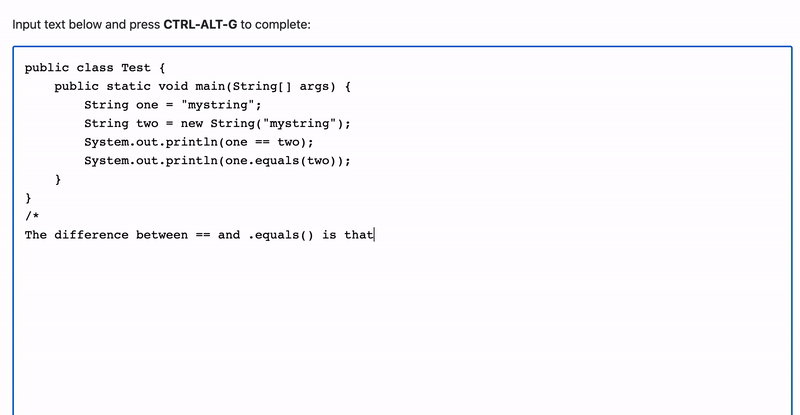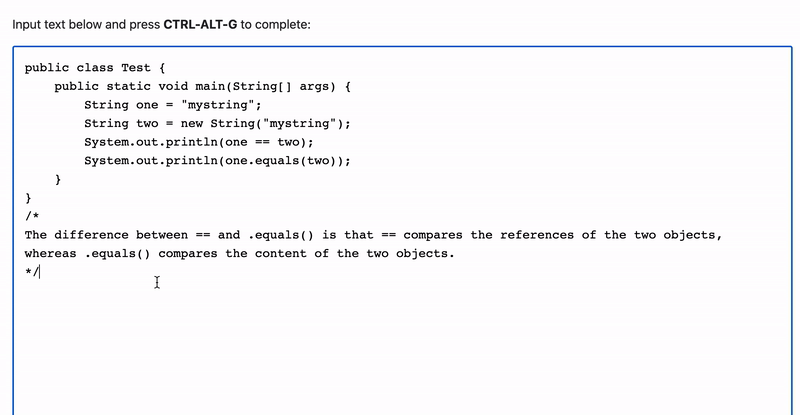
I'll break down the Javascript below if you'd like to make this yourself.
First, set up HTML with a <textarea>:
<p>
<label for="codearea">Input text below and press <b>CTRL-ALT-G</b> to complete:</label>
</p>
<textarea id="codearea" rows="40" cols="100"></textarea>
Grab the text box in Javascript:
const textarea = document.getElementById("codearea");
Set up a generate() function that runs a big fat API call to Codex using fetch():
function generate(userInput) {
textarea.style.cursor = "progress"; // loading wheel
fetch('https://api.openai.com/v1/completions', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Authorization': 'Bearer YOUR_API_KEY'
},
body: JSON.stringify({
'model': 'code-davinci-001', // replace with a different model as needed
'prompt': userInput,
'temperature': 0,
'max_tokens': 100,
'top_p': 1,
'frequency_penalty': 0.3, // stop the model from repeating itself
'presence_penalty': 0,
'stop': ["\n\n"] // Stop sequence
})
})
.then((response) => response.json()) // Get JSON from the response
.then((data) => {
const choice = data.choices[0].text; // This is the response
console.log(choice); // Log to console
textarea.style.cursor = "text"; // Change the cursor back
textarea.value += choice; // Add the response to the textarea
console.timeEnd("generate"); // See how long it took
});
}
The "stop sequence" above is a string which, when generated, will cause the model to stop. Sometimes Codex continued to generate code past what I intended, so I recommend setting the stop sequence to \n (for single-line completions) or \n\n (for writing short functions).
Finally, bind the generate() function to a keyboard shortcut (I use Ctrl-Alt-G):
document.onkeyup = function(e) {
if (e.ctrlKey && e.altKey && e.which == 71) {
console.time("generate"); // Time the result
generate(textarea.value); // The prompt is set to the value of all the code so far
}
};
Speed vs. Accuracy
Using console.time(), you can measure the latency of the API call. Most single-line completions for me took about a second. Multi-line completions took about five to ten seconds, depending on the request and length of response.
The API felt pretty sluggish to me, so I looked into using other models besides DaVinci (the most powerful one). OpenAI recently released code-cushman-001, which is much faster at the cost of some accuracy.
"Cushman" performed exceedingly well on single-line completions, taking ~500ms to produce nearly the exact same response as DaVinci. But when asked to write small functions, Cushman struggled and often produced buggy and error-prone code.
Closing thoughts / future exploration
Despite the fact that Ghostwriter and Copilot are so expensive, the Codex API is completely free! If you don't have access but want to build the project, sign up for the beta here.
Codex also has other capabilities -- the "insert text" and "edit text" functions were recently released. If I have more time in the future, I could change the front-end to let the user make these requests. Automatic detection of when a user wants a suggestion, rather than needing to press a keyboard shortcut, could also be helpful.
My initial dream for this project was to build something like Copilot or Ghostwriter - but is free and open source. I'm really excited to see what's coming in the future of AI code generation!


